AWS AI Factories target data sovereignty in customer data centers
Dedicated on-premises systems are aimed at governments and enterprises needing local training, compliance and lower latency


Artificial intelligence (AI) infrastructure is moving beyond the question of how many chips a company can buy. For large enterprises, governments and AI developers, the harder question is whether they can assemble enough power, cooling, networking and storage to make those chips work together.
That is turning local AI capacity into a data-center-scale project. The most demanding customers are no longer looking at small graphics processing unit (GPU) clusters. They want dedicated facilities that can train or fine-tune models while keeping critical workloads close to their own systems.
“The goal of AI factories, unlike dedicated local zones or local zones, is to bring really big computing infrastructure to the system,” said Chris McEvilly, senior solutions architect for hybrid edge at AWS. “We’re talking about 134 kilowatts per rack, which is a bit ridiculous, and is growing.”
“The starting point for an AI factory is around 3,000 GPUs,” he said. “The biggest AI factory we have at the moment is a million GPUs, so that gives you an idea of the scale.”
He said smaller deployments, including AWS Outposts, are more suitable for local inference. AI factories are designed for large-scale tasks, including local training and fine-tuning, in which many accelerators require high-performance networking and storage.
An AI factory can involve several tens of racks and, in some cases, hundreds. The number depends on the configuration, GPU type and the power density of each rack. The cost also reflects the scale.
Ben Lavasani, senior go-to-market (GTM) specialist for hybrid cloud and sovereign AI at AWS, said the dedicated infrastructure comes with a minimum commitment.
“Although we have pay-as-you-go pricing behind that, there’s a minimum amount,” Lavasani said. “Around $200 million over five years would be what we’ve been looking at for building this out.”
He said the final scope would depend on the services, site requirements and capacity needed by the customer. AWS would first need to assess whether a site could handle the infrastructure.
“I’d say something in the order of months, not weeks, but it certainly is not going to be years,” he said.
McEvilly cited Project Rainier, the AI factory built for Anthropic, as a reference case. AWS made the system available to the customer within a year. The launch involved half a million GPUs.
The scale of those deployments shows why the AI factory model is aimed at a narrow group of customers. It is not a shortcut for companies testing AI for the first time, but a way for organizations with large, sustained AI workloads to secure dedicated compute capacity.
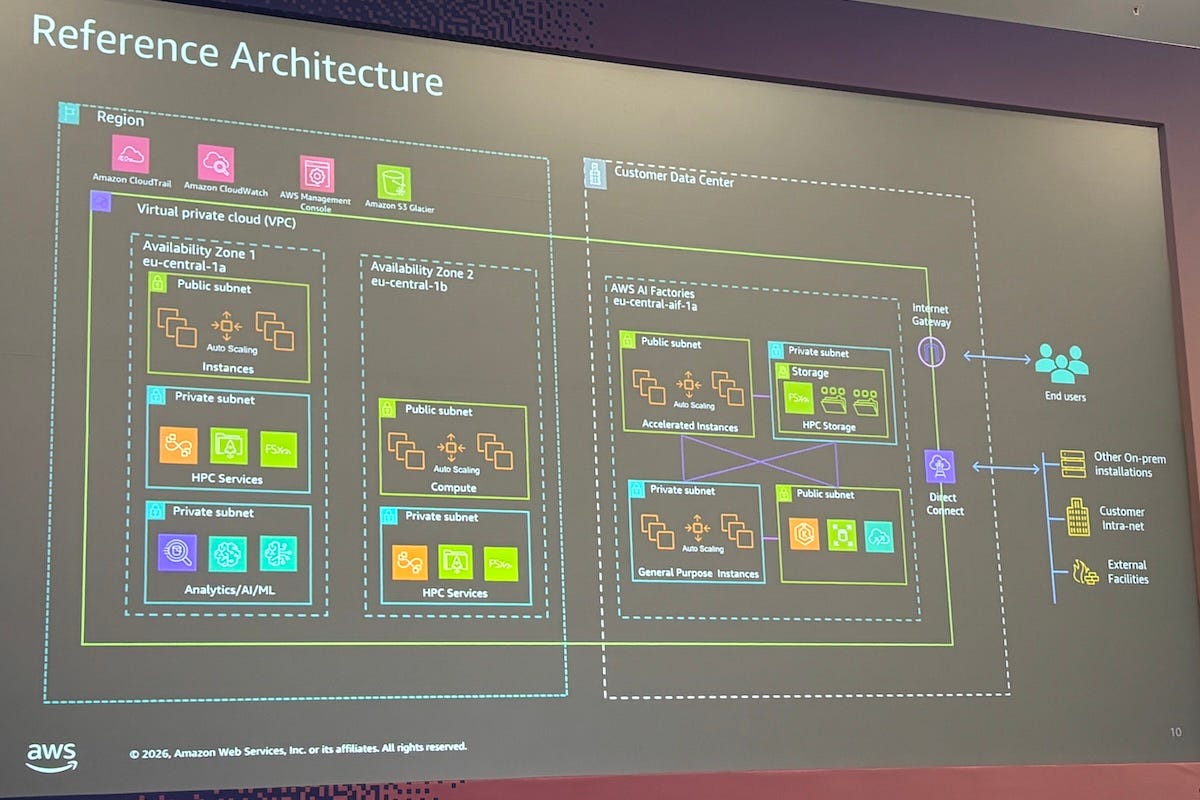
AWS AI Factories, launched last December, provide dedicated on-premises AI infrastructure in customer data centers. The service combines Nvidia accelerated computing, AWS Trainium chips and high-performance networking for large-scale AI training and deployment, while supporting data sovereignty, compliance and low-latency requirements.
Data control demand
The comments were made during a chalk talk at AWS Summit London on April 22. The session, titled “Scaling GPU Orchestration for AI Factories with Nvidia Run:ai,” focused on how large AI workloads can be deployed across local, cloud and hybrid environments.
One of the clearest use cases is data sovereignty. Governments, regulated industries and large enterprises increasingly want greater control over where data resides, who can access infrastructure, and how model weights are protected.

“Digital sovereignty is a huge topic,” Lavasani said. “There are a lot of concerns from governments, regulators and specific industries about how you are using data and AI, where your data is and how you are managing the end-to-end capabilities.”
AWS cloud regions can solve many of these problems today, but they do not cover every geography or every type of workload. AI factories are intended to extend AI infrastructure into locations where customers need local control, lower latency or a dedicated environment.
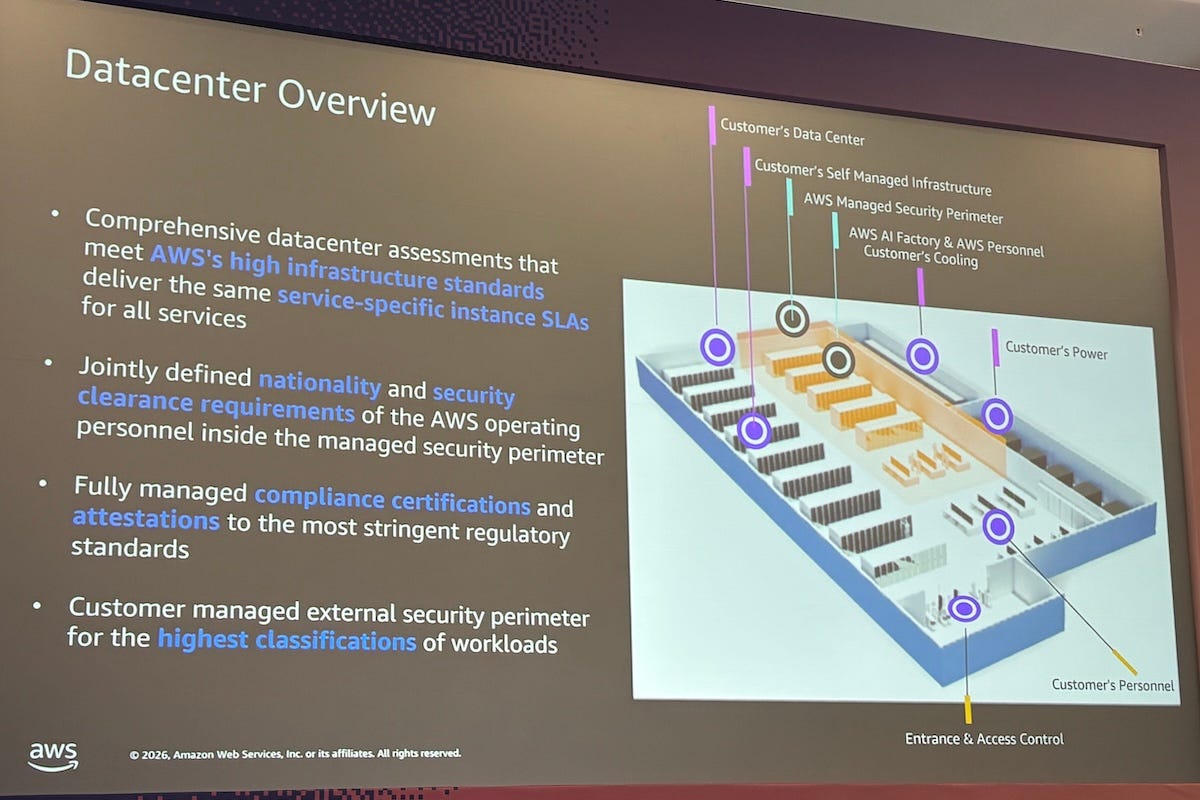
“We would install this as a secure perimeter within your data-center environment or a chosen data center of your choice,” Lavasani said.
In that model, the customer provides the surrounding facility, including power, cooling and networking. AWS operates the AI factory within a secure perimeter and manages the underlying infrastructure.
“You control access to the AI factory,” McEvilly said. “It’s your security outside and your engineers that manage the applications on it. AWS manages the actual infrastructure and the hypervisors.”
He said that separation is central to the operating model. The customer manages applications, while AWS manages hardware, firmware updates, hypervisors and infrastructure operations.

For some customers, data sovereignty may also extend to staffing. Lavasani said some organizations may require AWS employees who manage the infrastructure to hold specific security clearances or to be of a particular nationality.
He said the model is also meant to reduce the burden of building AI infrastructure from scratch. Companies trying to assemble their own AI systems face long cycles in sourcing, supplying, deploying, and managing hardware.
Those build cycles do not involve GPUs alone. Large AI deployments require storage, networking, security systems, accelerators, data-center capability and operational support. Multiple vendor relationships can slow companies moving from AI pilots to production workloads.
That is why AI factories are likely to appeal first to customers with heavy AI demand, strict compliance requirements and existing data-center commitments.
Orchestrating scarce GPUs
The second challenge is using those GPUs efficiently. Large AI systems can waste expensive compute capacity if workloads are poorly scheduled or if different teams compete for the same chips without a shared allocation model.
Nvidia Run:ai is designed to address that problem by managing AI and machine-learning workloads across different environments. It helps decide which workloads get access to GPU resources, when they run and how capacity is shared.
“Run:ai is a third-party tool from Nvidia that allows you to orchestrate and deploy AI workloads across AWS and other EKS [Amazon Elastic Kubernetes Service] environments,” McEvilly said. “It’s an orchestration tool for machine-learning and AI workloads.”

He said Amazon EKS is AWS’s managed service for running Kubernetes, the open-source system for managing containerized applications. Run:ai works one level above that by focusing on GPU usage.
He said this matters when customers have GPU capacity spread across several locations. Some organizations may have on-premises GPUs, regional cloud capacity, local zones, and AI factories. Run:ai can help orchestrate those resources as a more consolidated environment.
There are still practical limits. Lavasani said customers should benchmark their workloads in AWS regions rather than expect a small trial AI factory, because the infrastructure is too large and too dedicated for a proof-of-concept test.
“For benchmarking, you should do that in a region,” he said. “These instances and services are all available in regions today.”
Upgrade cycles will also be incremental. McEvilly said AWS would be responsible for capacity management and could roll in new racks when customers need more GPUs. Customers are expected to forecast capacity needs a few months ahead.
Accelerator choice is another constraint. Lavasani said AI factory chips currently follow what is available in AWS regions, mainly Nvidia GPUs and AWS Trainium chips. Other accelerators may be considered, but regional availability is likely to determine what can be deployed.
For enterprise customers, the next phase of AI infrastructure will depend on more than access to advanced chips. The bigger test will be whether they can secure sufficient power, manage GPU utilization, and navigate sovereignty, cost, and supply-chain constraints simultaneously.